今天要和大家拆解的,是摩根士丹利4月19日发布的一篇重磅报告——《Rise of the AI Agent – Global Implications》,原文73页。

这篇研报的核心结论只有一句话:AI基础设施的下一阶段,瓶颈不再是GPU,而是CPU、内存、基板和设备。
如果你觉得这句话听起来有点反直觉,那就对了。过去两年,整个市场的叙事都是"英伟达、HBM、台积电",GPU是绝对的主角。但摩根士丹利这次换了一个视角——当AI从"生成"走向"自主行动"(也就是Agentic AI,智能体AI),系统真正的瓶颈正在从算力本身,转移到"协调算力"这件事上。
而"协调"这件事,不归GPU管,归CPU管。
一、从"生成"到"行动",工作量被重新分配
摩根士丹利把智能体AI拆成了三个支柱:大脑(LLM,跑在GPU上)、调度(Orchestration,跑在CPU上)、知识(Memory,跑在内存和存储上)。

生成式AI时代,用户问一个问题,GPU吐出一个答案,流程简单,CPU只是"辅助"角色。但智能体AI不一样——它要规划任务、调用外部API、检索数据、执行代码、再反思结果、必要时循环迭代。英伟达CEO黄仁勋在今年3月的GTC 2026上说了一句很精准的话:CPU不再只是支持模型,它在驱动模型。
摩根士丹利援引乔治亚理工和英特尔的联合研究指出:在智能体工作负载中,CPU端处理占端到端延迟的比例可以高达50%到90%。换句话说,GPU很多时候是"空等CPU把活干完"。这个数字如果成立,意味着过去几年所有关于GPU利用率的假设都要重新算。
二、CPU的增量市场有多大
摩根士丹利给出了一个全新的测算框架,把数据中心CPU分成三类:
第一类是头节点CPU(Head Node),就是直接挂在GPU机架上的CPU,比如英伟达Grace、Vera。假设到2030年全球部署500万颗AI加速器,每个GPU板配两颗高端CPU,单颗均价5000美元,这部分TAM大约500亿美元。
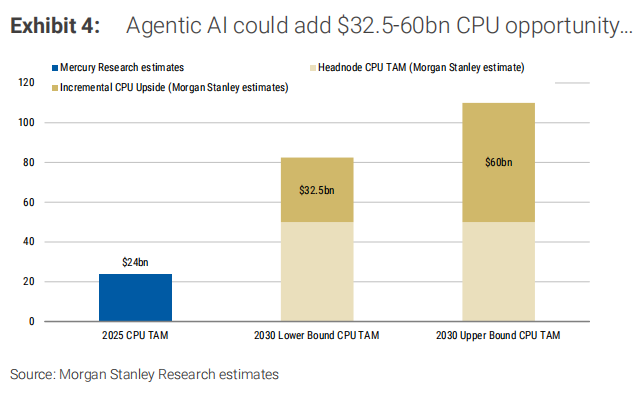
第二类是调度CPU(Orchestration),这是智能体AI完全新增的需求。摩根士丹利假设每个GPU需要2-3颗额外的CPU-heavy节点,核心数从现在的136核(Arm AGI CPU)涨到2030年的200-300核,单颗均价3000美元。这部分TAM在300-450亿美元之间。
第三类是存储节点和网络节点上的其他CPU,TAM大约25-150亿美元。
三类加起来,2030年数据中心CPU总市场规模将达到825亿到1100亿美元,其中智能体AI直接贡献的增量是325亿到600亿美元。
如果按英伟达黄仁勋"2030年AI基础设施投资3-5万亿美元"的更激进假设,CPU TAM甚至可能冲到2000-4500亿美元。
三、内存重估:DRAM从被动存储变主动组件
这是整篇研报最让我觉得有意思的部分。
Sam Altman说过一句话:"AI真正的突破不是更好的推理,而是持久的记忆。" 摩根士丹利把这句话翻译成了产业语言——智能体AI的竞争力,正在从"模型性能"转向"上下文记忆能力"。
因为智能体要连续运行、跨会话保留状态、在多个agent之间共享记忆、从过去的交互中学习。这意味着内存不再是GPU旁边的被动缓存,而是一个独立的、持续活跃的系统层。
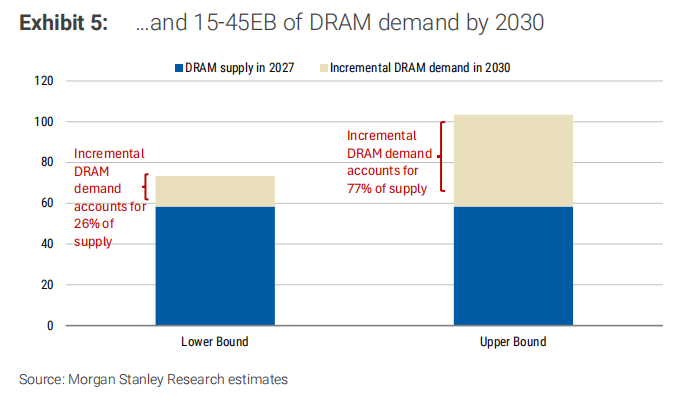
摩根士丹利测算,到2030年智能体AI将带来15-45 EB(艾字节)的增量DRAM需求,这个数字相当于2027年全年DRAM供应的26%到77%。注意,这是在HBM之外的纯CPU端DRAM需求。
具体路径是:英伟达Vera CPU单颗支持1.5TB LPDDR5X内存,整机柜可达400TB;AMD EPYC 9005单颗支持6TB DDR5,加上CXL扩展可到8TB。摩根士丹利假设到2030年,每颗调度CPU平均挂载1.5TB(基础场景)到3TB(乐观场景)DRAM,乘以10-15百万颗新增CPU,就是这个量级的需求。
四、ABF基板:一个被低估的结构性周期
ABF基板曾经是一个PC驱动的周期性行业——2015年PC占整个ABF需求的70%。但摩根士丹利认为,到2030年,服务器CPU、GPU、ASIC、网络芯片加起来将占ABF终端需求的75%以上。
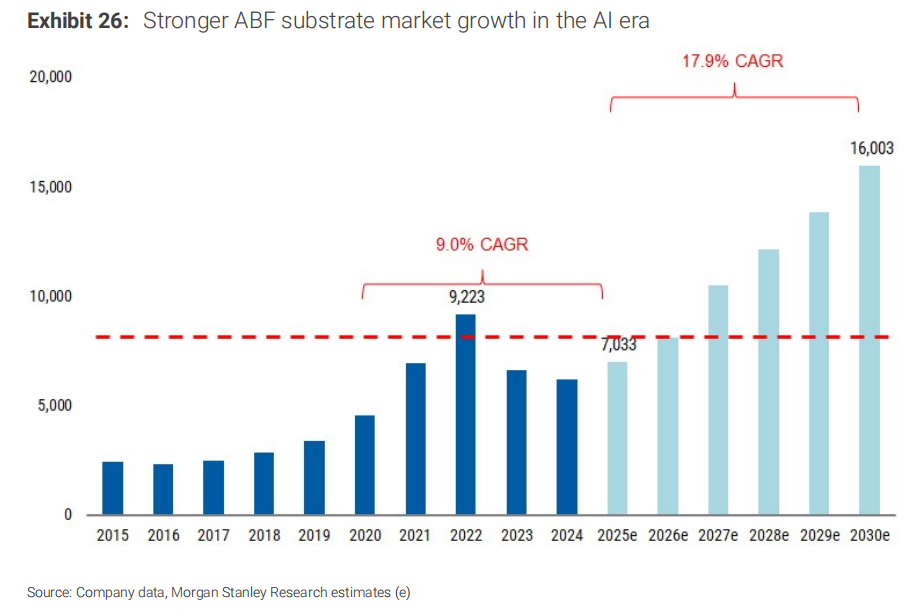
更关键的数字是增速。摩根士丹利把ABF基板市场2025-2030年的年复合增长率,从原来的16.1%上调到17.9%,对比2020-2025年的9.0%,这是一次决定性的提速。供需缺口方面,如果没有新增产能,智能体AI带来的增量CPU需求将把2030年的供需缺口从原来的7%扩大到15%。
这意味着ABF供应商在未来几年不仅能涨价,而且涨价不是靠博弈,而是靠"能生产多少卖多少"的结构性短缺。
五、具体标的:摩根士丹利的四个关键上调
摩根士丹利这次同时上调了四家公司的目标价:
SK海力士从130万韩元上调到170万韩元,2026-2028年EPS预测分别上调24%、37%、78%。
三星电子从25.1万韩元上调到36.2万韩元,2026-2028年EPS预测上调45%、74%、121%。
三星机电(SEMCO)从50万韩元上调到71万韩元,核心逻辑是MLCC和ABF双AI敞口。
这里面最有意思的其实是三星电子。摩根士丹利说,三星的HBM改善+商品内存超级周期+LTA长协锁价,这三个因素叠加起来,让市场对三星的盈利预期严重滞后。2027年预测市盈率只有5倍。
美股这边,摩根士丹利明确表态:"我们偏好通过AI赋能者(英伟达、Broadcom、美光、SanDisk)来获取智能体AI敞口,而不是直接买CPU的英特尔和AMD。" 理由很简单——CPU股(英特尔、AMD)的估值是23-64倍市盈率,而英伟达只有18倍FY27预测PE,内存股只有5-9倍PE。
CPU故事最干净的受益者是AMD(云CPU市占率已经超过英特尔达到53%),但摩根士丹利认为AMD的股价更多绑定GPU故事,而英特尔更多绑定代工故事,所以两家都给Equal-weight。真正纯粹的AI赋能敞口反而在内存和GPU龙头身上。
我的理解:
这份研报最有价值的地方,不是那些具体的TAM数字,而是它换了一个分析AI产业链的坐标系。
过去两年市场的思维方式是"算力稀缺→买GPU→买HBM→买台积电",这是一条单线逻辑。但当AI开始"自主行动",问题就变成了:谁来协调这一切?谁来记住上下文?谁来在数千个agent之间传递状态?
答案不再是一个芯片,而是一整个系统。CPU、DRAM、ABF、基板、MLCC、BMC、CPU socket、电源管理、散热——这些过去被认为是"配角"的环节,现在每一个都在被智能体AI重新定价。
对普通投资者来说,这意味着两件事。
第一,英伟达叙事之外,还有一大批"隐形受益者"值得研究。 摩根士丹利列出的名单很长:三星机电和Ibiden的ABF基板、Unimicron的CPU基板、Aspeed的BMC(全球CPU服务器BMC市占率70%)、Montage的内存接口(全球市占率36.8%)、Yageo的MLCC、Lotes和FIT的CPU socket、ASML的EUV光刻、KLA的量测设备。这里面每一个环节,都不是泡沫级别的估值,但增长曲线正在被智能体AI重新定义。
第二,周期性品种的周期正在被结构性拉长。 以ABF基板为例,历史上这是一个典型的周期性行业,跟着PC和服务器走,3-4年一个循环。但如果摩根士丹利的判断正确——AI驱动的ABF上行周期能持续到2030年——那么市场对这类标的应该用"结构性成长股"的估值框架,而不是"周期股"的估值框架。这种框架切换本身,就是估值重估的驱动力。
当然,所有这些判断都建立在一个假设之上:智能体AI真的会按照摩根士丹利描绘的路径扩散开来。这条路径的关键节点是2026-2027年企业端的Agent部署,以及长协(LTA)能否在2027年真正锁住内存和基板的价格。如果这两件事兑现了,这份研报就是一张不错的路线图。